













En el desarrollo de soluciones de inteligencia artificial generativa, dos términos aparecen una y otra vez: RAG (Retrieval-Augmented Generation) y Fine-tuning. Ambos métodos permiten personalizar el comportamiento de los modelos de lenguaje (LLMs), pero lo hacen de formas radicalmente distintas.
El fine-tuning modifica el modelo desde dentro, reentrenándolo con datos específicos, y el RAG lo complementa desde fuera, dándole acceso a información nueva y actualizada en tiempo real.
A continuación comparamos las diferencias clave entre ambas técnicas, sus ventajas, limitaciones y los escenarios en los que cada una resulta más adecuada, incluidos los enfoques híbridos RAFT que han ganado terreno en implementaciones empresariales.
TL;DR: RAG y fine-tuning resuelven problemas distintos. RAG conecta el modelo a fuentes externas actualizadas sin reentrenamiento: arquitectura de referencia para datos dinámicos y privados. Fine-tuning ajusta los parámetros internos para moldear comportamiento, tono y formatos de salida, con la ventaja de responder sin overhead de retrieval. En datos de alta frecuencia de cambio, RAG gana. En dominios estables con alto volumen de consultas o requisitos de formato estrictos, fine-tuning puede ser más eficiente. Los enfoques híbridos RAFT combinan ambas técnicas cuando ninguna sola es suficiente.
Qué hace cada técnica de IA
Fine-tuning
El fine-tuning consiste en reentrenar un modelo preexistente con datos adicionales para adaptarlo a un dominio o tarea concreta.
Por ejemplo, si un modelo general sabe escribir correos o responder preguntas básicas, tras un proceso de fine-tuning puede transformarse en un asistente experto en derecho fiscal español o en atención al cliente para una marca específica.
En la práctica, esto implica modificar los parámetros internos del modelo para que aprenda los patrones lingüísticos, el tono y la terminología del nuevo conjunto de datos.
Un caso de uso diferenciador del fine-tuning es la latencia de inferencia. A diferencia de RAG, que introduce un paso de retrieval antes de cada respuesta, un modelo fine-tuned responde directamente desde sus parámetros sin consultar fuentes externas. Esto lo hace preferible en sistemas donde el overhead de retrieval es inaceptable: pipelines de procesamiento en tiempo real, integraciones con APIs síncronas con restricciones estrictas de tiempo de respuesta, o cualquier arquitectura donde la latencia acumulada importa. También es el método de elección cuando el modelo debe seguir formatos de salida muy específicos, como JSON estructurado o terminología técnica de un dominio cerrado, donde la consistencia nativa supera lo que el prompting sobre RAG puede garantizar.
RAG
Por otro lado, el RAG (Retrieval-Augmented Generation) no toca el modelo en sí. En lugar de modificarlo, le da acceso a una base de conocimiento externa (bases de datos, documentos internos o la web).
Cuando el usuario hace una pregunta, el sistema busca información relevante, la "inyecta" en el contexto del modelo y este genera la respuesta final combinando su conocimiento previo con los datos recién recuperados.
Así, el modelo RAG no necesita ser reentrenado como el fine-tuning: simplemente aprende a consultar las fuentes adecuadas en tiempo real.
RAG es especialmente relevante cuando la organización trabaja con datos privados o confidenciales que no pueden bakearse en los pesos del modelo. La base de conocimiento vive fuera, se actualiza de forma independiente y el modelo la consulta en inferencia. Desde la perspectiva de costes, esta arquitectura tiene una ventaja clara en proyectos de volumen moderado: elimina el coste y el tiempo de reentrenamiento. A cambio, genera costes recurrentes por tokens de entrada en cada consulta, un factor que se vuelve relevante a partir de cierto umbral de volumen de llamadas.
En resumen:
- Fine-tuning = el modelo aprende nueva información.
- RAG = el modelo consulta información nueva cuando la necesita.
Impacto en la personalización
El fine-tuning proporciona una personalización profunda y duradera. Tras el reentrenamiento, el modelo incorpora de forma nativa los conocimientos, el estilo y las reglas de tu dominio. Es ideal cuando quieres que tu IA "piense y hable" exactamente como tu empresa, sin depender de fuentes externas.
Por ejemplo, una aseguradora puede crear un modelo ajustado que responda con su tono corporativo y conozca todos sus productos, incluso sin conexión a internet.
RAG, en cambio, ofrece una personalización dinámica. El modelo mantiene su estructura original, pero puede acceder a información actualizada cada vez que se le consulta. Esto es fundamental para empresas que manejan datos en constante cambio, como precios, regulaciones o catálogos de productos.
En lugar de reentrenar el modelo cada vez que algo cambia, simplemente se actualizan las fuentes de información que RAG consulta.
Precisión y actualización del conocimiento
El fine-tuning ofrece respuestas más naturales, rápidas y consistentes porque el conocimiento está integrado directamente en el modelo. Sin embargo, su mayor desventaja es la obsolescencia: una vez entrenado, el modelo no sabe nada nuevo. Si la información cambia, hay que repetir el proceso de fine-tuning (costoso y lento).
RAG soluciona ese problema al separar el conocimiento del modelo. La IA consulta fuentes externas actualizadas antes de responder, lo que garantiza precisión incluso cuando los datos cambian a diario.
No obstante, su dependencia de la calidad de esas fuentes implica que la respuesta puede variar según la disponibilidad o relevancia del contenido recuperado.
Por resumirlo así, el fine-tuning sabe menos, pero lo sabe muy bien; RAG sabe más, pero depende de dónde lo busca.
Costes e implementación
El fine-tuning requiere un proceso de entrenamiento que consume recursos de hardware (GPUs), tiempo de ingeniería y validación humana. También necesita mantener versiones actualizadas del modelo, lo que implica costes de almacenamiento, energía y personal especializado.
Es una inversión mayor, pero a cambio ofrece control total y rendimiento óptimo en tareas repetitivas.
El RAG, por su parte, es más rápido y económico de implementar. No hay que reentrenar el modelo, solo configurar la infraestructura que conecta el LLM con la base de datos vectorial o la fuente de información. Su coste principal proviene del mantenimiento de esas fuentes y de las consultas realizadas, pero no de entrenamiento intensivo.
Por eso, RAG suele ser la mejor opción para equipos que buscan reducir inversión inicial y acelerar la puesta en marcha de un sistema de IA.
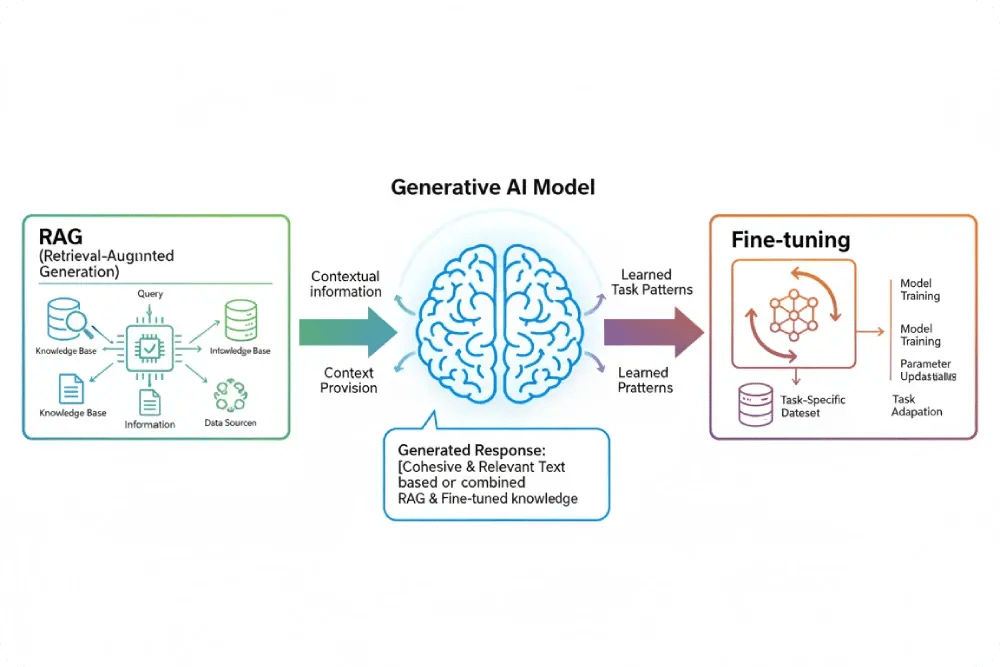
Cuándo usar fine-tuning y cuándo RAG
El fine-tuning es la opción adecuada cuando la prioridad es la coherencia, la precisión y la personalización total del modelo.
Funciona mejor en entornos donde el conocimiento cambia poco, como atención al cliente interno, análisis jurídico, generación de documentación técnica o traducción especializada. Su mayor ventaja es que el modelo se comporta de manera consistente y responde en segundos, sin depender de fuentes externas.
El RAG, en cambio, brilla cuando la empresa necesita mantener la información siempre actualizada o trabaja con datos extensos y cambiantes. Si gestionas documentación viva (manuales, políticas, precios o normativas), esta arquitectura permite conectar la IA a las fuentes internas sin necesidad de reentrenarla.
Es ideal para asistentes de conocimiento, buscadores corporativos, chatbots documentales o aplicaciones donde el contexto cambia a diario.
Un factor adicional que ha ganado peso es el volumen de consultas. En proyectos con miles de llamadas diarias, el coste acumulado de tokens de entrada en cada consulta RAG puede superar, a largo plazo, la inversión inicial de fine-tuning. Herramientas como las pasarelas LLM permiten controlar ese gasto con políticas de cuota y caching semántico, pero no lo eliminan: son gobernanza, no alternativa arquitectónica. Las organizaciones con cargas de trabajo estables y alto volumen están recalibrando la ecuación: el fine-tuning deja de ser "caro" cuando su coste se distribuye entre millones de inferencias sin retrieval. Este análisis requiere números reales de la carga de trabajo de cada sistema, no estimaciones genéricas.
En muchos casos, las empresas optan por una combinación híbrida: un modelo entrenado mediante fine-tuning con el estilo y tono de la marca, y una capa RAG encima que aporta información reciente. Esta mezcla ofrece lo mejor de ambos mundos: personalidad y precisión.
RAFT: cuando fine-tuning y RAG no son suficientes por separado
La dicotomía RAG vs fine-tuning tiene una tercera salida con nombre propio: RAFT (Retrieval-Augmented Fine-Tuning). El término procede de una investigación de UC Berkeley (Zhang et al., 2024) y describe una receta de entrenamiento específica, no un simple "combina los dos".
En RAFT, el modelo no solo accede a documentos en inferencia como en RAG estándar. Durante el entrenamiento, se expone al modelo a preguntas acompañadas de un conjunto de documentos que incluye tanto el documento relevante como varios documentos distractores. El objetivo es que el modelo aprenda a:
- Identificar y citar la secuencia correcta del documento relevante.
- Ignorar los documentos distractores recuperados junto al relevante.
- Razonar sobre el contexto recuperado con respuestas en formato chain-of-thought, no solo extraer texto.
El resultado es un modelo que domina su dominio gracias al fine-tuning y trabaja con retrieval de forma robusta, incluso cuando la calidad del retrieval es imperfecta. Los benchmarks del paper original muestran mejoras consistentes sobre RAG estándar en conjuntos de datos como PubMed, HotpotQA y Gorilla (Zhang et al., arxiv 2403.10131).
¿Cuándo tiene sentido aplicar RAFT? Cuando el dominio es suficientemente estable para invertir en fine-tuning, los datos son privados o especializados (candidato natural a RAG), y la calidad del retrieval no es perfecta o varía según la fuente. El overhead operativo de RAFT es real: requiere construir un dataset de entrenamiento con distractores sintéticos y ejecutar el proceso de fine-tuning. No es una arquitectura de prototipo rápido. Para casos donde el corpus tiene entidades con relaciones explícitas y la trazabilidad de cada respuesta es crítica, GraphRAG ofrece una alternativa basada en grafos de conocimiento con menor overhead de entrenamiento.
Tabla de diferencias entre RAG y Fine-tuning
| ASPECTO | RAG | FINE-TUNING |
| Funcionamiento | Busca información en fuentes externas en tiempo real | Se entrena de nuevo con datos específicos |
| Actualización del conocimiento | Continua y dinámica: accede siempre a datos actualizados | Estática: requiere entrenamiento si la información está obsoleta |
| Coste de implementación | Bajo a medio, no requiere GPUs para entrenamiento | Alto, necesita recursos de cómputo y especialistas |
| Tiempo de despliegue | Rápido, basta con conectar fuentes de datos | Más lento, depende del tamaño del dataset y el entrenamiento |
| Precisión y consistencia | Según la calidad y relevancia de las fuentes añadidas | Alta consistencia en tareas muy específicas |
| Mantenimiento | Actualización de fuentes o índices | Entrenamientos periódicos |
| Personalización | Superficial, respuestas adaptadas al contexto | Profunda, el modelo adopta comportamiento y estilo propios |
| Escenarios ideales | Datos cambiantes, búsqueda documental, chatbots corporativos | Procesos estables, atención personalizada, modelos especializados |
| Ejemplo típico | Asistente conectado a documentación interna actualizada | Modelo ajustado al tono y conocimiento de una marca |
| Latencia de inferencia | Mayor latencia por el paso de retrieval en cada consulta | Sin overhead de retrieval: responde directamente desde parámetros |
| Coste a alto volumen | Costes recurrentes por tokens de entrada en cada llamada | Inversión inicial alta, coste marginal por consulta bajo |
| Enfoque híbrido (RAFT) | Aporta el pipeline de retrieval; el modelo aprende a filtrar distractores | Aporta el ajuste; el modelo aprende a razonar sobre documentos recuperados |
RAG, fine-tuning o RAFT: cómo elegir en la práctica
La regla operativa es más sencilla de lo que parece: RAG es para el conocimiento factual y cambiante; fine-tuning es para la maestría en la forma y el razonamiento especializado. RAFT entra cuando necesitas ambas cosas y puedes asumir el coste del entrenamiento.
Antes de decidir, cuatro variables concretas: frecuencia de actualización de los datos, volumen de consultas diarias, tolerancia a la latencia de respuesta y nivel de personalización de comportamiento requerido. Ninguna arquitectura gana en todos los ejes. La elección correcta minimiza el coste total con los constraints operativos del sistema, no la que parece más sofisticada en el paper.
Para los equipos que necesitan implementar cualquiera de estas arquitecturas, la variable crítica no es la técnica sino el perfil que la ejecuta. Un ingeniero de machine learning que ha trabajado con RAG en producción aplica criterios distintos a uno que ha hecho fine-tuning en proyectos de laboratorio. Esa diferencia de experiencia práctica es el implementation gap que BCG documentó en enero de 2025: el 75% de empresas que probó implementar IA no vio resultados. La técnica elegida importa menos que la capacidad de ejecución certificada detrás.
Cómo acceder al talento que domina estas técnicas
Independientemente de que ya sepas si necesitas RAG o fine-tuning, lo cierto es que ambos perfiles son técnicos especializados, como ingenieros de machine learning, arquitectos de datos, científicos de IA y desarrolladores con experiencia en LLMs.
Es decir, perfiles que ciertas empresas, por necesidades, objetivos o, simplemente, por presupuesto, no pueden asumir en plantilla por sus elevados salarios y su demanda internacional.
Ahí es donde entra Shakers.
Nuestra plataforma reúne una comunidad de más de 10.000 freelancers tecnológicos verificados, entre ellos ingenieros especializados en RAG, fine-tuning y desarrollo de aplicaciones basadas en IA generativa.
Cada profesional ha pasado por un proceso de evaluación técnica exhaustivo para asegurar que las empresas trabajen solo con los mejores.
Lo que te ofrecemos es un modelo flexible, freelance, que te permite incorporar el perfil exacto que necesitas, durante el tiempo que lo necesitas, sin asumir costes fijos ni procesos largos de selección.
Implementar una solución avanzada de IA no tiene por qué implicar inversiones millonarias ni meses de desarrollo.
Con Shakers, puedes acceder a talento freelance especializado en RAG y fine-tuning, capaz de construir, entrenar o integrar modelos de inteligencia artificial personalizados según los objetivos y el presupuesto de tu empresa.
¿Cómo funciona Shakers?
Acceder al talento de un RAG/Fine-tuning freelance es cuestión de unos clics. Solo debes crear tu proyecto en la plataforma, detallando objetivos técnicos, retos de desarrollo y el tipo de colaboración que necesitas.
Nuestra IA de matching se encarga del resto, mostrándote los perfiles que mejor se adaptan a tu equipo, tanto por habilidades técnicas como por cultura de trabajo.
Cuando encuentres al candidato ideal, solo tendrás que cerrar la colaboración, agendar una primera reunión y empezar a trabajar juntos.
El mundo de la contratación tecnológica está en plena revolución. No renuncies a los mejores perfiles de liderazgo técnico por cuestiones de presupuesto y súmate al modelo Fractional con Shakers, la casa del freeworking.


